-
[논문 리뷰] Heterogeneous Graph Attention Network (HAN)Machine Learning/etc. 2023. 7. 28. 04:30
논문: Heterogeneous Graph Attention Network
일단 짚고 넘어가야 할 건, 나는 GNN 뉴비다. 공부한지 한 달도 안 되었다....
그러므로 많이 부족한 점이 보여도 양해 바람.
Abstract
- 그래프. superior performance. 근데 heterogenous graph에 대해선 연구 부족
- 그럼 Heterogenous graph가 뭐냐?
- node와 link(edge)의 type이 다른 것
- 왜 그런가?
- heterogeneity와 rich semanic information이 GNN 디자인을 challenge하게 만듦
- 최근 attention 매커니즘이 각광, 여러 분야에 쓰임
- 우리는 hierarchical attention 을 기반으로 한 heterogeneous GNN을 제안함. based on:
- node-level attention
- node와 그것의 이웃 기반 meta-path 사이의 중요도를 배우는 것이 목적
- semantic-level attention
- 다른 meta-path간의 importance를 배우는 것이 목적
- 여기서 meta-path란?
- 간단하게 말하면 path의 종류!
- HMSG 논문에서는 다음과 같이 정의함:
- an ordered sequence of node types and edge types, which is used to capture specific semantic information of the graph
- 즉, 아래 그림의 (b)임
- node-level attention

- node와 semantic level의 attention을 둘 다 함으로써 node와 meta-path의 중요도가 fully considered될 것
- 그 후 우리 모델은 만든 meta-path 기반 이웃들로부터 hierarchical하게 feature를 aggregating함으로써 node embedding을 만들게 될 것.
- 세 가지의 real-world data로 실험 수행, SOTA 찍었을 뿐만 아니라 graph 분석에서 good interpretability 달성 (이건 무슨 근거로 알수있는걸까?)
Introduction
- real-world data는 graph structure
- 뭐 앱스트랙과 똑같은 얘기…
- attention 각광받다! 이거 사용한 GAT novel하다!
- real-world에 더 가까운건 heterogeneous graph인데 연구 많이 안이루어지고 있음
- → Heterogeneous information network (HIN) 인데 편의상 Heterogeneous graph라고 부르겠음.
- Heterogeneous graph는 많은 이해가능한 정보와 rich semantics를 갖고 있어서 많은 데이터마이닝 task에 사용됨.
- Meta-path: 두 object간을 잇는 복합적인 관계(relation)
- semantic을 잡는 데에 많이 사용되는 구조
- 예시로, figure 1 (IMDB)

- 두 영화 간의 관계는 두 meta-path로 정해짐:
- Movie-Actor-Movie (MAM): co-actor relation
- Movie-Director-Movie (MDM): 동일한 감독에 의해 만들어진 영화!
- → meta-path에 따라 node간의 관계는 다른 의미를 가지게 됨
- heterogenours graph의 복잡성 때문에 기존 GNN은 바로 적용 불가
- heterogenous graph를 위한 attention mechanism을 사용한 GNN을 만들기 위해, 다음을 고려:
- Heterogeneity of graph
- HG의 본질적인 속성
- 다른 type의 node는 다른 특성 가짐. 그들의 feature는 다른 feature space에서 실패할수도. (fall은 fail의 오타인듯?)
- IMDB에서, actor의 feature는 성별, 나이, 인종을 가지고 있음
- movie의 feature는 각본과 배우를 가지고 있음.
- → 어떻게 동시에 복잡한 structural information을 다뤄야 하고 다양한 feature information을 보존해야 하는지가 과제
- Heterogeneity of graph
- Semantic-level attention
- meta-path에 따라 각기 다른 semantic 정보들이 추출됨
- eg. 위의 IMDB에서, <터미네이터>는 MAM에 의해 <터미네이터2>와 연결될 것
- 반면 MYM(Movie-Year-Movie)에 의해서는 와 연결될 것. (개봉 연도가 같으므로)
- 그러나 영화 장르를 분류해야 한다면, MAM이 더 중요한 역할을 할 것.
- ⇒ 따라서, 각 meta-path의 중요도를 배우기 위해 semantic-level attention을 수행
- Node-level attention
- heterogeneous graph에서 노드는 다양한 type의 relation에 의해 연결됨(meta-path)
- meta-path에 기반한 다양한 이웃들이 존재
- 어떻게 이웃 사이의 subtle difference를 구분할 수 있을까?
- 각 노드에 대해 meta-path에 기반한 이웃의 중요도를 배우기 위해, node level attention을 수행
- HAN은 다음 세 가지의 과정 거침
- Type-specific transformation matrix: 다른 type의 node feature를 동일한 space로 projection
- Node-level attention
- Semantic-level attention
Relative Works
일단 패스
Preliminary
Def 3.1. Heterogeneous Graph

- object set V, link set $\mathcal{E}$
- node type mapping function $\phi: \mathcal{V} \rightarrow \mathcal{A}$
- node i의 type은 $\phi_i$로 나타냄
- link type mapping function $\psi: \mathcal{E} \rightarrow \mathcal{R}$
- A와 R: 미리 정의된 obj type과 link type
- |A| + |R| > 2
Def 3.2. Meta-path
- defined as a path in the form of

- (A_1A_2…A_{l+1}로 줄여 씀)
- composite relation $R = R_1 \circ R_2 \circ \cdots \circ R_l$ (A_1과 A_{l+1} 사이)
- $\circ$: composition operator on relations
Def 3.3. Meta-path based Neighbors
- node i와 meta-path $\Phi$가 주어졌을 때,
- $\mathcal{N}_i^\Phi$: i에 대한 meta-path based neighbors, node의 set으로 구성
- node i 자기 자신도 포함!!
- meta-path에 따라 다른 structural information 양상을 드러냄.
이 때 동일한 type의 node들끼리만 neighbor가 될 수 있는 것 같음. (=homogeneous neighbors)- -> 근데 이렇게 되면 후술할 projection 과정이 의미가 없어지므로 아닌 것 같음.
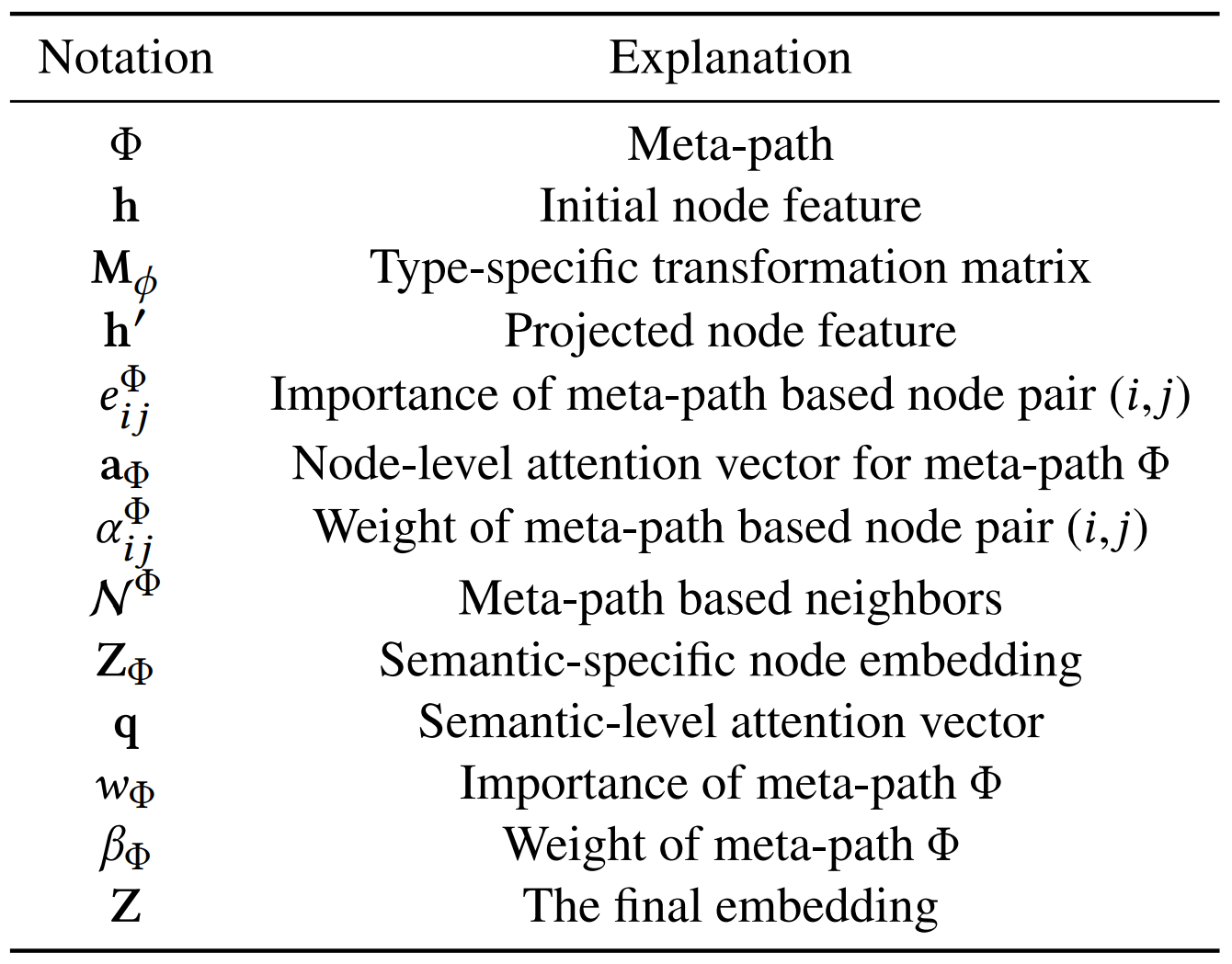
Notation 요약
The Proposed Model
- novel semi-supervised graph neural network
- 왜 semi-supervised인가?
- hierarchical attention structure
- node-level → semantic-level
- 왜? 순서가 바뀌면 안되었던 것인가? 둘이 바뀌는 게 더 직관적인데..
- → semantic attention을 할 때 node attention 기반 node embedding이 필요했기 때문

- node-level attention → meta-path based neighbors의 weight 얻음
- aggregate해서 semantic-specific한 node embedding 얻음
- → 무엇을 기준으로 aggregate 하는가?
- sematnic-level attention으로 meta-path간의 차이를 배우고, 특정 task에 대해 node embedding의 optimal weighted combination을 얻음 (이게 attention)
4.1 Node-level Attention
- 사실 GAT와 99.9% 동일하다.
- 참고) GAT의 self-attention

- 각 node의 meta-path based neighbors는 task에 따라 node embedding을 배우는 데에 다른 역할을 하고, 다른 중요도를 보임
- node의 heterogeneity 때문에, node 종류에 따라 다른 feature space 가짐. 그러므로, (node) type-specific transformation matrix $M_{\phi_i}$를 만들어서 다른 type의 node를 동일한 feature space로 projection함

- h_i와 h_i`: original and projected feature of node i
- 그 후 self-attention 진행 (근데 self attention이 아닌데…? 그냥 feature이 같은 space 안에 있으면 self-attention인가?)
- meta-path $\Phi$로 연결된 node pair (i, j)가 있을 때,node attention \mathcal{e}_{ij}^\Phi : node i에게 node j 중 어떤 것이 중요한지를 배울 수 o

- att_node: attention을 수행하는 DNN
- 각 meta-path에 대해, 모든 node pair(i, j)가 att_node를 공유⇒ 그냥 dot product를 쓰면 안되나?
- → 각 meta-path에 대해 유사한 connection pattern이 존재하기 때문
- GCN과 node-attention
- GCN은 HW에 A까지 추가적으로 곱해주면서, 각 node의 embedding을 구성할 때 인접한 node의 정보만 반영되는 것이 특징.

출처: https://littlefoxdiary.tistory.com/17 - node-attention은 그 인접한 node 중에서도 중요한 node를 배워서 node embedding을 만들 때 그 중요도를 반영
- $\mathcal{e}_{ij}^\Phi$ : asymmetric → query와 key가 바뀌면 값이 달라지니까~
- → critical property of heterogenous graph (음 개인적으로 공감 안됨;;)
- 논문에서는 e를 이렇게 구함 (||는 concatenation, a는 node-level attention vector, sigma는 activation function)

-
- node attention $\mathcal{e}_{ij}^\Phi$ : node i에게 node j 중 어떤 것이 중요한지를 배울 수 o
- 이 때 masked attention 이용하여 구조적 정보 주입
- 즉, $\mathcal{e}_{ij}^\Phi$를 계산할 때 $j \in \mathcal{N}_i^\Phi$인 j에 대해서만 계산 (즉, i와 meta-path based 이웃인 j에 대해서만 계산) → GATs과 유사!

- alpha 또한 asymmetric (당연함)
- node i의 이웃이 제각각이므로, normalized term(분모)는 달라짐
- node i의 meta-path based embedding은 neighbor의 projected features + coefficients(alpha)에 의해 aggregate → 그냥 attention이잖아..!!
- ~aggregate됨으로써 최종적으로 attention이 완성됨.

- $z_i^{\Phi}$가 node i의 최종적인 embedding이 됨
- aggregating process 그림으로 표현 vs GATs의 attention


- heterogeneous graph는 scale free한 속성을 가지기 때문에, graph의 variance는 꽤 높음
- 이 문제를 해결하기 위해 multihead attention 도입 → 더 stable해짐
- 단순히 여러 개의 head로 수행한 attention을 concatenation 한 형태

- meta-path set ${\Phi_1, \dots, \Phi_P }$이 주어졌을 때, attention 후에는 P개의 semantic-specific node embedding group(set?)을 얻을 수 있음. ${Z_{\Phi_1} \dots, Z_{\Phi_P} }$
4.2 Semantic-level Attention
- heterogeneous graph의 모든 node는 여러 type의 semantic information을 가지고,
- semantic-specific node embedding은 오직 node의 한 측면만 반영됨
- 더 comprehensive node embedding을 배우기 위해서는 우리는 meta-path에서 나온 multiple semantic을 fuse해야함
- ⇒ 그러니까 정리하면 meta-path 단위로 attention을 한번 더 돌리자는 이야기
- P개의 semantic-specific node embedding 그룹이 있을 때,
- 각 meta-path별 learned weight는 다음과 같음

- 절차를 자세하게 풀이하면:
- semantic-specific embedding을 nonlinear transformation (MLP 등) 으로 transform해줌
- semantic-level attention vector q
- 모든 semantic-specific node (동일한 meta-path를 가지는 node)에 대해 평균을 구함
- 모든 파라미터는 모든 meta-path, semantic-specific embedding에 동일하게 적용
- softmax function을 적용시켜 normalize

- 높은 beta값 → 더 중요한 meta-path라는 뜻
- introduction에서 소개했던 대로, meta-path $\Phi_{\mathcal{p}}$는 task마다 다른 weight를 가짐
- 위에서 구한 coefficient를 통해, final embedding $Z$를 구할 수 있음

- task에 따라 loss function을 다르게 짤 수 o
- semi-supervised node classification을 위해서는 아래와 같음 (cross-entropy)

- C: classifier의 parameter, y_L: label이 있는 set of node indices
- Y_l: labels, Z_l: embeddings of labeled nodes
- overall process

- 얘는 multi-head attention 안하나?
4.3 Analysis of the Proposed Model
- abstraction에서 나온거랑 동일한 이야기…. 다양한 type의 information을 다룰수 있다. 다른 type은 embedding은 mutual integration 등등을.. 강화시킬 수 있다.
- highly efficient, easily parallelized (attention이니까 당연.)
- node-level attention의 시간복잡도는 아래와 같음 (GAT와 동일)

- V: node 개수, E: meta-path based node pair
- F1, F2: row, coloumn of the transformation matrix (M)
- 행렬곱 기준. 앞 항은 동일한 feature space로 projection한 feature vector 계산식
- 뒤 항은 실제 node attention 계산식
- ⇒ linear to the number of nodes(V), meta-path based node pairs(E)
- hierarchical attention은 heterogeneous graph 전체적으로 공유됨 → scale에 영향X
- ⇒ inductive problem에 사용 가능 (GAT와 동일)
- 뭐 자기네들 모델이 좋다는 이야기 attention덕분에 중요도 체크 가능하다 어쩌구
Experiments
5.1 Datasets
- DBLP
- database, data mining, machine learning, information retrieval 분야의 논문에 대한 그래프
- node types: 14328 papers (P), 4057 authors (A), 20 conferences (C), 8789 terms (T)
- author feature: bow of represented of keywords
- meta-path: {APA, APCPA, APTPA}
- author feature: bow of represented of keywords
- ACM
- KDD, SIGMOD, SIGCOMM, MobiCOMM, and VLDB에 published된 paper
- 3개의 classes: Database, Wireless Communication, Data Mining
- node types: 3025 papers (P), 5835 authors (A) and 56 subjects (S)
- paper feature: bow of represented of keywords
- meta-path: {PAP, PSP}
- IMDB
- 영화 dataset
- 3개의 classes: Action, Comedy, Drama
- node types: 4780 movies (M), 5841 actors (A) and 2269 directors (D)
- movie feature: bow of represented of plots
- meta-path: {MAM, MDM}

5.2 Baselines
- 몇 개의 SOTA baseline을 비교
- HAN의 두 버전을 test
- DeepWalk
- random walk based network embedding method
- heterogeneity는 무시
- ESim
- heterogeneous graph embedding method
- 체크포인트 없어서 HAN의 weight를 가져다 씀
- metapath2vec, HERec
- heterogeneous graph embedding method
- 모든 meta-path에 대해 test후 best performance를 기록
- GCN, GAT
- homogeneous graph embedding method
- 모든 meta-path에 대해 test후 best performance를 기록
- HAN_nd
- node-level attention 삭제, 각 neighbor에 대해 동일한 importance 부여
- HAN_sem
- semantic-level attention 삭제, 각 meta-path에 대해 동일한 importance 부여
- → 그냥 GAT가 아닌가..
5.3 Implementation Details
- randomly initialize parameters
- Adam optimizer
- learning rate: 0.005, regularization parameter: 0.001
- dim of q(semantic-level attention vector): 128, K=8
- dropout of attention: 0.6
- early stopping with a pateience of 100
- 모든 algorithm에 대해 embedding dimension은 64
5.4. Classification

- KNN classifier (k=5)
- variance가 높아서 10번 수행 후 평균값을 기록
- Macro-F1: 라벨별 f1 score를 산술평균
- Micro-f1: accuracy와 동일하다고 함..?
- ACM, DBLP에서는 GCN이 GAT보다 성능이 더 좋은데 왜 논문에서는..
- 심지어 .ACM에서는 HAN_nd보다도 GCN이 더 낫다. (근데 이건 뭐 예측 가능)
- DBLP에서 HAN의 성능차이가 두드러짐 → APCPA meta-path가 다른 것보다 월등하게 중요하기 때문 (그래서 GCN과 HAN_nd의 성능차이도 났던 거군)
5.5 Clustering
- K-Means algorithm 사용
- 구한 node embedding 바탕으로 K=#of classes 설정해두고 알고리즘 적용
- NMI, ARI: 클러스터링 평가 척도
- cluster의 initial centroid 중요하기 때문에 10번 돌려서 평균을 구함

- 성능 HAN이 젤 좋음
- attention 두 개 중 하나를 빼면 성능이 떨어짐
- GAT와 HAN_sem의 차이는 단지 various type node를 하나의 feature space로 projection 시켰느냐 아니냐 인 것 같은데… 성능차이가 나서 놀랐다.
5.6 Analysis of Hierarchical Attention Mechanism
Analysis of node-level attention
- ACM data중에 하나(P831) 고름, attention값 분석
- <Screening and Interpreting Multi-item Associations Based on Log-linear Modeling>
- meta-path: Paper-Author-Paper

- P699, P133: 모두 Data Mining
- P2384, P2328: Database
- P1973: Wireless Communication
Analysis of semantic-level attention

- DBLP와 ACM에 대해, 각 meta-path에 대해 NMI를 구한 후 attention value와 비교
- → positive correlation
- 근데 그래프 말고 수치로 보여주지… 자세한 내용이 없어서 아쉽.
5.7 Visualization

5.8 Parameters Experiments

- embedding of dimension: 너무 많으면 performance drop → Z는 suitable dimension이 있을 거라고 추측. q는 overfitting
노션에 정리해둔 걸 그대로 가져오다보니 가독성이...
'Machine Learning > etc.' 카테고리의 다른 글
Back-Propagation (오차 역전파법) : 논문을 바탕으로 개념 정리 (0) 2022.01.22 선형 회귀 (Linear Regression) : (3) 모델 성능 평가 2 (가설 검정) (0) 2021.07.21 선형 회귀(Linear Regression) (2) : 모델 성능 평가 1 (평가 지표) (0) 2021.07.02 선형 회귀(Linear Regression) (1) : 파라미터 추정 (0) 2021.06.26